
Il web marketing continuerà a crescere.
Non si tratta di un fenomeno nuovo, ma se ci pensi è sconvolgente. Ha messo in discussione le regole della comunicazione e della vendita e si evolve nel contesto digitale. Un tempo, l’intelligenza artificiale, i Big Data, le pubblicità che cambiano da consumatore a consumatore, erano concetti che sembravano quasi fantascienza. Oggi tutto questo è la normalità e fa parte delle principali tendenze del Digital Marketing.
Il business è fatto di comunicazione e di relazioni tra le persone. Che siano riunioni, occasioni di pubbliche relazioni, contesti creati apposta per la realizzazione di partnership, la ricerca di prodotti o servizi e la vendita, la linfa degli affari è il networking.
Il web marketing porta tutte queste pratiche nel contesto digitale, dunque non stravolge ma evolve. Se vuoi che la tua azienda rimanga competitiva in questo nuovo panorama online, che non dà alcun segno di voler retrocedere, devi adattarti alle ultime innovazioni.
Dove c’era il contesto sociale ora c’è il social network, dove c’era il cartellone ora c’è l’advertising sul web, dove c’erano le interviste a campione ora ci sono i dati degli utenti. Tutti questi strumenti hanno gli stessi scopi di quelli del passato, semplicemente sotto una nuova forma.
L’avvento di Internet ha reso il mondo a portata di click. Ha dato la possibilità di accorciare le distanze e di comunicare facilmente con chiunque. Il web marketing sfrutta al massimo questa potenzialità, facendoti raggiungere un bacino più ampio del tuo pubblico target. Soprattutto ti consente di farlo rapidamente.
Dunque, non puoi più permetterti di non sfruttare le tecniche e le tecnologie del web marketing per la tua impresa o attività.
Sarebbe come continuare ad andare a cavallo mentre tutti gli altri si muovono in auto.
Sono sicuro che tu non vuoi restare a bordo campo a guardare come sono bravi gli altri a giocare la partita.
Perciò ecco quello che devi fare: informati, impara e adotta le strategie migliori per ottenere dei concreti vantaggi per il tuo business. Ti stai chiedendo da dove iniziare? In questa guida al web marketing ho incluso tutte le informazioni che devi sapere, è un po’ lunga ma molto dettagliata perché non volevo trascurare nulla.
Se, invece, stai cercando un modo più immediato per far evolvere la tua azienda e le tue modalità di comunicazione così da ottenere più clienti e più vendite, clicca il pulsante qui sotto e scorpi la mia consulenza personalizzata.
Cos’è il Web Marketing?
Prima di entrare nel dettaglio delle strategie vorrei chiarire il significato di web marketing e darne una definizione.
Il web marketing si riferisce al processo di promozione della tua attività attraverso l’utilizzo di Internet e dei suoi strumenti in maniera pianificata e strategica. Questo metodo include l’utilizzo dei motori di ricerca, dei social media, dell’e-mail marketing, delle metodologie di comunicazione e di tutte le tipologie di contenuti che essi supportano, testuali, visivi e video.
Per sintetizzare il concetto di marketing digitale si può dire che è quel processo che serve per portare il tuo messaggio agli utenti, in maniera efficace e attraverso i canali online.
Oggi è in assoluto il modo che meglio ti può aiutare a promuovere la tua azienda e a mettere i tuoi prodotti o servizi alla portata dei consumatori.
Analizzandolo nel dettaglio, il web marketing assume molte forme, dai banner pubblicitari alle promozioni via e-mail, dalle strategie di ottimizzazione delle tue pagine web fino ai post sui social media.
Insomma, nella sua completezza necessita di un grande lavoro, di moltissime competenze e di tempo sia per imparare che per restare aggiornati sulle continue novità.
Il web marketing è un immenso contenitore di opportunità che puoi sfruttare per il tuo personal branding e per creare quella relazione di fiducia con i tuoi potenziali clienti. A patto che tu sappia quali siano le corrette strategie da applicare.
Ma di questo non devi preoccuparti, perché ti aiuterò io.
Nel corso della mia carriera mi sono misurato ogni giorno, e continuo a farlo tutt’ora, con tutte le tecniche e le tecnologie relative al marketing e alla vendita.
Per farti capire ancora meglio il valore di una digital strategy nel business di oggi, vediamo gli elementi del web marketing e come si differenzia da quello tradizionale.
Differenza tra web marketing e marketing tradizionale
Vorrei partire brevemente dalle origini del marketing per mostrarti qual è stata la sua evoluzione da quello conosciuto come tradizionale a quello che si fa oggi tramite il web.
Studiare questo aspetto è molto importante per capire quali benefici si possono trarre oggi dalle strategie di web marketing rispetto a ciò che era possibile fare in passato.
Quando parliamo di marketing ci riferiamo a un metodo di comunicazione.
Nel marketing tradizionale venivano utilizzati gli eventi in presenza, i cartelloni pubblicitari, i manifesti, volantini, le radio, la tv e tutti quei supporti che abbiamo ancora oggi ma che non hanno a che fare con il mondo di Internet.
Il web marketing ha inserito nella comunicazione tutti i canali disponibili sul web e continua a farlo man mano che ne vengono introdotti di nuovi.
Tuttavia, ha fatto molto più di questo.
Le tecnologie non riguardano solamente i canali attraverso i quali viene veicolato il messaggio aziendale. La vera rivoluzione risiede nel fatto di poter monitorare e analizzare tutte le attività di promozione messe in campo.
Come? Attraverso i programmi di tracciamento e analisi dei dati.
La vera rivoluzione è quella di poter avere un riscontro diretto e quasi in tempo reale di tutte le attività promosse per vedere cosa funziona, cosa deve essere corretto e il numero esatto di obiettivi raggiunti.
Oltre a questo, troviamo un’altra serie di benefici come i costi ridotti, la possibilità di valutare gli investimenti più proficui, una grande quantità di opzioni tra cui scegliere per la comunicazione e la possibilità di raggiungere quotidianamente il proprio pubblico.
Ma è proprio necessario fare tutto questo?
Perché fare Web Marketing?
A questa domanda segue una facile risposta. Perché Internet oggi è necessario.
Prova a pensare ad un’azienda completamente scollegata dal web. Gli utenti non potrebbero trovare informazioni sugli orari di apertura, non potrebbero seguire il lancio delle novità in tempo reale, non potrebbero nemmeno leggere le recensioni e le testimonianze di altri clienti.
In sintesi, quell’azienda è come se non esistesse.
Il tuo preciso dovere è di evitare tutto questo e di renderti quanto più visibile al tuo target di riferimento. Solo così potrai incrementare le vendite e, di conseguenza, il tuo profitto.
Tutto questo senza contare la costante presenza degli utenti sui social media e il fatto che, nel 2021, si è registrato il record italiano degli acquisti su e-commerce. Il commercio digitale continua ad aumentare e, di conseguenza, la presenza dei consumatori sul web.
Se vuoi che i tuoi prodotti e servizi vengano visti e acquistati da un pubblico sempre più vasto, allora non puoi fare a meno che essere presente online attraverso le strategie di comunicazione più efficaci.
Attraverso il web puoi creare funnel di vendita, ovvero percorsi che ti permetteranno di trasformare dei semplici visitatori in clienti fedeli pronti a comprare i tuoi prodotti o servizi.
Le strategie di marketing, che vedremo tra poco nei prossimi paragrafi, servono proprio per fare in modo che il potenziale cliente conosca le tue offerte, si affezioni al tuo marchio e si convinca che la soluzione migliore per lui, o lei, sia proprio comprare da te.
Inoltre, attraverso le strategie digitali hai la possibilità di tenere monitorati gli andamenti, quindi capire se quello che stai facendo funziona. Questo ti permette di incrementare gli investimenti dove serve, sistemare ciò che non sta producendo risultati e valutare tutti gli obiettivi raggiunti.
Credi ancora che non sia vantaggioso?
Quali sono i vantaggi del web marketing
Abbiamo già messo molta carne al fuoco, ma ora ti voglio riassumere in modo schematico tutti i vantaggi del digital marketing:
- Raggiungi il pubblico giusto: questo aspetto non è affatto da sottovalutare perché il marketing tradizionale ti permetteva di selezionare il pubblico di destinazione solamente in modo sommario. Il web marketing, invece, ti consente di raggiungere proprio il cliente ideale per il tuo prodotto o servizio basandoti sulle sue informazioni personali, sugli interessi, sui bisogni e anche sulle sue paure.
- Costruisci il tuo Personal Branding: l’immagine dell’azienda è molto importante per attirare potenziali clienti che ancora non ti conoscono. Puoi manovrare tutti i canali del digital marketing per creare esattamente l’immagine che vuoi trasmettere della tua azienda scegliendo i contenuti da condividere, il tono di voce e il messaggio da veicolare.
- Misuri i risultati: ogni strategia di marketing online ti permette di monitorare una grande quantità di dati che ti aiutano a capire se la tua campagna ha raggiunto l’obiettivo che ti eri prefissato, se va modificato qualcosa, se ha raggiunto il pubblico giusto, quante interazioni ha avuto, ecc.
- Riduci i costi: ogni attività di marketing ha dei costi, è inevitabile. Ma se prima pubblicare una pagina su un quotidiano cartaceo ti poteva costare anche centinaia di euro, ora puoi attivare una campagna sponsorizzata su Facebook con pochi euro e raggiungere già un risultato interessante. Quindi non ti dirò che il digital marketing è gratis, ma che è economicamente molto più conveniente rispetto a tutti gli altri strumenti a tua disposizione.
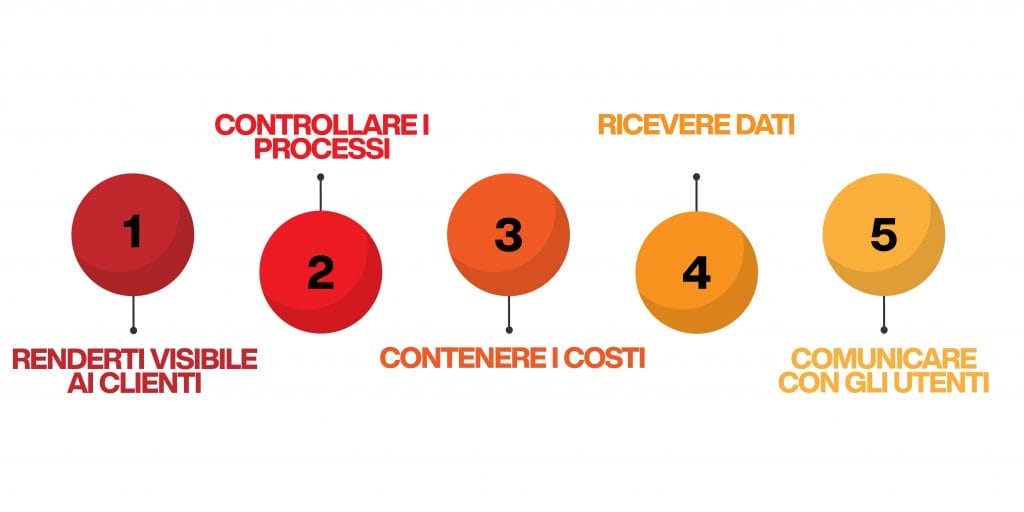
Perché dovresti investire nel web marketing
Dopo aver riassunto i benefici, voglio schematizzarti anche i motivi per cui dovresti scegliere questa strada:
- Raggiungi un vasto pubblico: non solo le strategie di digital marketing ti consentono di raggiungere il pubblico giusto, ma puoi anche ampliare notevolmente il tuo bacino di utenza. Se con un quotidiano potevi raggiungere un bacino di utenza limitato, con il web marketing puoi mostrare la tua azienda al mondo intero.
- Implementi altre strategie: il web marketing non va utilizzato da solo, ma va conciliato con tutte le altre attività che svolgi per far fiorire il tuo business. In particolare, con il mondo delle vendite. Impostare una campagna di web marketing ti consente di raccogliere dati e di preparare il pubblico in modo tale che anche il lavoro di tutti gli altri reparti possa migliorare.
- Aumenti la brand awareness della tua azienda: grazie al web marketing puoi accrescere la notorietà del tuo marchio nella mente dei consumatori e, di conseguenza, spingerne sempre di più a diventare inconsciamente tuoi clienti. Perché di base conoscono già il tuo brand avendolo visto più e più volte durante i loro viaggi virtuali sui motori di ricerca o sui social network.
- Costruisci relazioni profonde con i clienti: oltre ad ampliare il bacino di utenza, il web ti consente anche di creare delle relazioni che accrescano sempre di più la fiducia nei consumatori e che ti permettano di fidelizzare i clienti già acquisiti.
Con quali strategie è possibile fare marketing sul web
Il web marketing comprende una serie di attività e di strumenti che puoi adottare per rendere più visibile la tua azienda, intercettare e attirare i tuoi potenziali clienti, promuovere i tuoi prodotti e servizi, portare i consumatori fino al momento della conversione in clienti effettivi.
Il modo migliore per trovare clienti oggi è affidarsi al metodo di Inbound marketing, che si basa una logica di attrazione del cliente. Quindi immagina di veicolare dei contenuti che sappiano parlare ai consumatori e in grado di cogliere la loro attenzione. Quando le persone vedono che nelle tue offerte trovano la soluzione ai loro problemi, saranno automaticamente predisposte a interessarsi ai tuoi prodotti o servizi fino ad arrivare all’acquisto.
Questo è un processo lungo, fatto di molte fasi e che richiede l’applicazione di svariate strategie, tra cui:
- SEO: la Search Engine Optimization è quella serie di attività che permette ai siti web di ottenere visibilità sui motori di ricerca sfruttando parole chiave, link, tag e tanti altri elementi presenti all’interno di un sito;
- PPC: le campagne a pagamento incentivano il traffico attraverso la pubblicazione di annunci che appaiono quando l’utente effettua una ricerca su Google;
- Content Marketing: la produzione di contenuti di valore è fondamentale per aumentare la brand awareness e stabilire un contatto quotidiano con il proprio pubblico;
- E-mail marketing: l’e-mail è uno dei contatti più personali che puoi avere con i potenziali clienti o con quelli già acquisiti, ti permette di inviare offerte personalizzate e altamente mirate;
- Social Media Marketing: l’uso sapiente dei social media ti consente di creare l’immagine aziendale che vuoi veicolare, di rimanere in contatto con gli utenti e di essere a disposizione per fornire informazioni o chiarire dubbi;
- Mobile Marketing: le strategie di web marketing che si occupano di sfruttare i dispositivi mobile con SMS, app, native mobile advertising, qr code, ecc.;
- Funnel Marketing: per aumentare le vendite devi guidare i consumatori nella cosiddetta canalizzazione di vendita, ovvero il percorso utile a portare il cliente fino al momento dell’acquisto e poi verso la fidelizzazione.
Ora vediamo le principali logiche dell’Inbound marketing e, nel dettaglio, ognuna delle strategie attraverso le quali promuovere il tuo brand e far crescere la tua azienda.

Le logiche dell’Inbound marketing
Prima di tutto vorrei riportare la definizione di Inbound marketing data da HubSpot, promotore di questo metodo: “Si tratta di una metodologia di business che attrae clienti creando contenuti ed esperienze personalizzate e di valore”.
Contenuti, personalizzazione e valore sono i tre punti chiave per riuscire a comunicare con i clienti, attrarli e trattenerli. Questo è lo scheletro su cui andare a definire tutta la strategia di marketing utilizzando gli strumenti e i canali del web che offrono, oggi, le opportunità necessarie per entrare in contatto con i potenziali clienti, creare interazione e favorire gli acquisti.
La logica che sta alla base dell’Inbound marketing è chiamata Modello Flywheel, o volano, che sradica la concezione tradizionale della classica canalizzazione di vendita per andare oltre. Infatti, il volano è un metodo che mette al centro di tutto il cliente che non è più solo un punto di arrivo ma anche un punto di partenza per nuove e future acquisizioni. Seguire questa logica significa che non ci si ferma più solo al singolo processo di acquisto ma che è necessario impostare un ulteriore processo con cui andare ad instaurare una relazione positiva con il cliente anche dopo che la vendita è stata conclusa.
Forse adesso stai pensando che tutto questo potrebbe essere una perdita di tempo e che la cosa migliore è passare al cliente successivo. Invece no, o meglio, certo che devi passare ai clienti successivi ma il vantaggio di mantenere vive le relazioni con quelli esistenti è che la probabilità che tornino a comprare da te è più alta. Ogni acquisizione ha un costo, più sono gli acquisti che ogni cliente effettua e più riesci ad ammortizzare il costo inziale.
Inoltre, se questi clienti si trovano bene con la tua azienda e sono soddisfatti dei prodotti e del servizio di assistenza, diventeranno loro stessi promotori del tuo marchio. Per te questo vuol dire ulteriore pubblicità e possibili nuove acquisizioni a costi molto bassi o nulli. È come se i tuoi clienti diventassero influencer spontanei del tuo marchio.
Per arrivare a questi risultati, però, occorre impostare una strategie completa che renda efficienti ed efficaci tutte le fasi di attrazione, coinvolgimento e fidelizzazione.
Vediamole di seguito.
SEO
La strategia SEO (Search Engine Optimization) è quell’insieme di attività che ti permette di lavorare sul posizionamento su Google del tuo sito web nei risultati che vengono forniti dai motori di ricerca. In particolare da Google.
A cosa serve?
A farti trovare sul web dagli utenti e a portare un aumento del traffico verso il tuo sito.
È provato come il traffico di cui un sito gode dipenda moltissimo dalla posizione in cui si trova tra i risultati di Google. Infatti, tu stesso quando cerchi qualcosa su Internet ti rivolgi alle pagine che trovi nelle prime posizioni, mentre sono sicuro che non controlli neanche nella seconda pagina di Google.
Perciò, se il tuo sito web non è presente in prima pagina gli utenti non ci arriveranno mai.
È chiaro quindi che trovarsi in prima pagina, meglio ancora se tra le prime posizioni, rappresenta un vantaggio competitivo a tutti gli effetti in termini di visibilità.
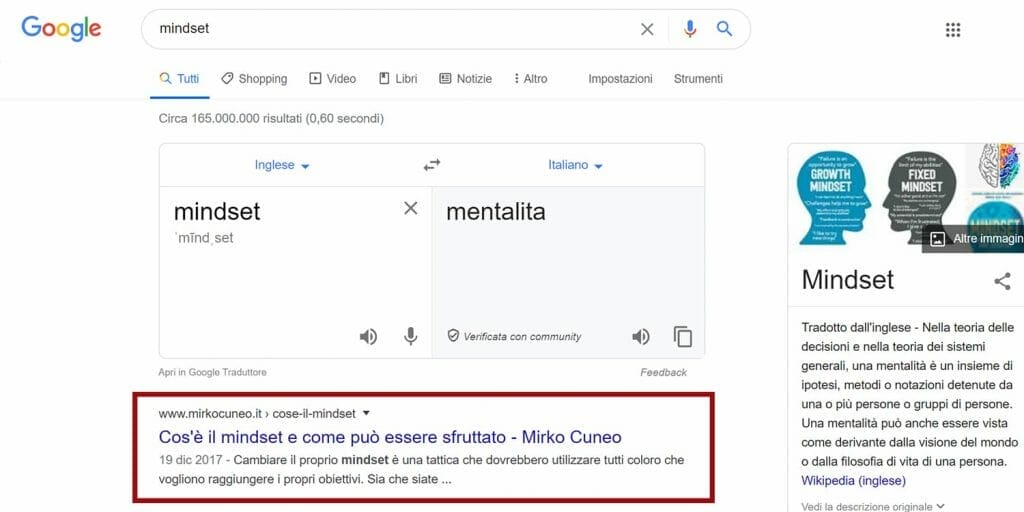
Nell’immagine qui sotto ti mostro gli ottimi risultati che può dare una strategia SEO davvero ben fatta. Ho digitato la parola mindset sulla barra di ricerca e il mio articolo appare proprio come primo risultato di Google.
Essere in prima posizione non è facile, soprattutto se non sai come farlo, ma è il risultato a cui devi puntare per il tuo sito web. Gli esperti SEO si occupano di capire come gestire l’algoritmo di Google restando aggiornati con tutte le novità che escono ogni mese. È un lavoro a tempo pieno che richiede anni di preparazione, uno studio continuo e l’esperienza fatta sul campo.
PPC
Per raggiungere ancora più visibilità un ottimo modo è la pubblicità. Si tratta di sponsorizzazioni a pagamento che ti permettono di aumentare il tuo bacino di utenti, quindi di attirare verso la tua azienda un numero maggiore di potenziali clienti. Infatti, ciò di cui hai bisogno per aumentare le tue vendite sono i lead, ossia i contatti da trasformare poi in clienti.
Come si acquisiscono i lead?
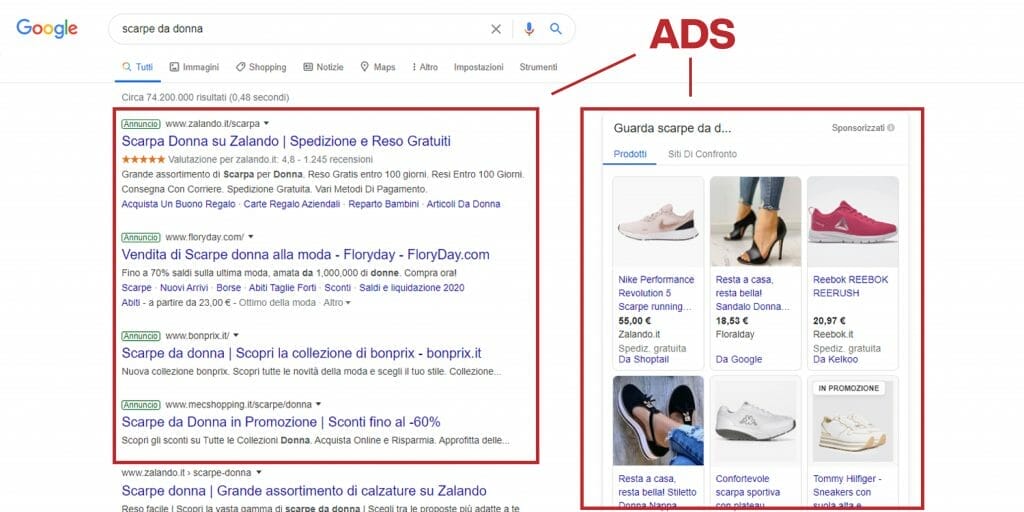
Un metodo veloce ed efficace è quello della pubblicità pay-per-click (PPC). Grazie a questa tecnica puoi creare degli annunci a pagamento che vengono mostrati nella parte superiore dei risultati forniti da Google.
Riconoscerli è molto facile. Si trovano prima dei risultati organici e sono contrassegnati dalla parola “Annuncio”.
Esattamente come per la SEO, anche le campagne PPC si posizionano sfruttando le parole chiave e appaiono di conseguenza quando gli utenti scrivono una determinata query sui motori di ricerca.
Sono tantissime le aziende che scelgono le campagne PPC proprio per la caratteristica che le contraddistingue dal resto della pubblicità online.
Nelle campagne pay-per-click paghi solamente quando un utente clicca sul tuo annuncio e per questo non spenderai mai più del dovuto. Grazie a questa tipologia di campagna puoi raggiungere il tuo pubblico ideale proprio nel momento in cui sta cercando la soluzione che tu puoi offrigli.
In termini di campagne a pagamento, puoi orientarti anche sul display advertising. In questo caso non pubblichi più un annuncio testuale ma sfrutti la potenza dell’immagine che ti aiuta a raggiungere obiettivi diversi come aumentare la brand awareness, incrementare il traffico sul tuo sito, trovare lead, ecc.
Ma alla base si qualsiasi annuncio o strategia di comunicazione che intendi veicolare c’è il marketing dei contenuti che vediamo nel prossimo paragrafo.
Content Marketing
Il content marketing è la strategia perfetta per fornire al tuo pubblico tutte le informazioni di cui ha bisogno e ti aiuta a creare l’immagine della tua azienda agli occhi del pubblico.
Nel momento in cui diffondi contenuti stai fornendo delle informazioni importantissime sulla tua azienda, sui tuoi prodotti o servizi così da farti apparire un esperto nel tuo settore e assicurarti un seguito di utenti.
Ricorda però che i tuoi contenuti devono essere di qualità se vuoi che interessino e trattengano l’utente. Ogni volta che scrivi una qualsiasi comunicazione devi sempre prestare attenzione a due variabili: quello che dici e quello che non dici. I temi che affronti e il modo di farlo sono la tua presentazione ai potenziali clienti, quindi le parole e le forme devono essere scelte accuratamente.
E non sto parlando solamente di articoli di blog. Sicuramente gli articoli testuali sono un ottimo canale per fornire informazioni dettagliate, ma pensa anche a infografiche, video, podcast, e-book, guide e anche le pagine o le schede prodotto presenti sul tuo sito.
L’obiettivo del content marketing è proprio quello di fornire informazioni utili, complete e interessanti al pubblico.
Grazie ai contenuti che pubblichi puoi indirizzare gli utenti da altre piattaforme fino al tuo sito web e, se avrai lavorato bene, è probabile che molti di loro si trasformeranno prima o poi in clienti.
Non preoccuparti se questo passaggio non avviene subito. Ricorda quello che ho detto prima sull’Inbound marketing, ci sono contenuti e modi di comunicare che si adatto alle varie fasi della canalizzazione e che hanno scopi differenti.
E-mail Marketing
Pensi che l’e-mail marketing sia una strategia superata? Assolutamente no!
Nonostante i canali di comunicazione siano aumentati negli ultimi anni, non posso negarlo, l’e-mail rappresenta ancora uno dei contatti più personali dei tuoi utenti.

Scopri come la mia agenzia può aiutarti ad aumentare le vendite della tua azienda
Aumentiamo le vendite della tua azienda
Miglioriamo le performance della tua azienda online
ADV: Creiamo campagne pubblicitarie con un ROI chiaro
Inoltre, l’e-mail ha potenzialmente un tasso di apertura molto alto, questo perché le persone utilizzano il proprio account di posta elettronica per interessi sia personali che professionali e la maggior parte di loro apre la casella diverse volte al giorno. La clausola è sempre quella di scrivere cose ritenute utili e interessarti da chi le riceve.
Per dare il via alla tua strategia di e-mail marketing devi, prima di tutto, ottenere una lista di iscritti grazie ad altre attività di marketing oppure alle visite che ricevi fisicamente in azienda.
I lead possono essere guadagnati sia tramite annunci a pagamento sia in modo organico, o anche attraverso pop-up e moduli di contatto presenti sul tuo sito web. Io ti consiglio di utilizzare più di un metodo perché quelli a pagamento ti aiutano a farti conoscere da più persone in meno tempo, mentre quelli organici consistono in una solida strategia a lungo termine. La cosa più importante per avere una mailing list che funziona è aspettare che siano le persone a decidere di iscriversi di spontanea volontà. Così hai la sicurezza che sono davvero interessante alle tue comunicazioni. Altrimenti verrai immediatamente riconosciuto come spam e questo potrebbe crearti problemi futuri e di reputazione.
Questi lead sono preziosissimi perché sono i contatti che utilizzerai nelle strategie di marketing successive.
Social Media Marketing
Il social media marketing racchiude tutte quelle operazioni di marketing che puoi attuare nel contesto dei social network. Nel corso degli anni questa disciplina è cresciuta sempre di più adattandosi allo sviluppo degli stessi social media.
Insieme all’e-mail marketing è l’altro canale che ti permette di entrare in comunicazione diretta con il tuo pubblico.
I social media ti permettono di condividere contenuti informativi ma anche di connetterti facilmente con gli utenti rispondendo alle loro domande e fornendo un aiuto specifico.
Sono tantissimi i social media tra cui puoi scegliere quando decidi di implementare questa strategia di marketing e ricorda che ognuno di questi ha le sue particolarità.
Vediamo insieme le piattaforme indispensabili per una strategia aziendale. Conoscerle è il primo passo per decidere quali contenuti pubblicare.

Uno dei social media più utilizzati è sicuramente Facebook. Questa piattaforma ti consente di pubblicare una grande quantità di contenuti.
Su Facebook puoi permetterti di scrivere dei post abbastanza lunghi nel momento in cui vuoi condividere un tutorial o delle informazioni specifiche su un prodotto o servizio.
Allo stesso modo, puoi pubblicare foto, immagini, grafiche, caroselli o video.
La varietà di contenuti ti permette di raggiungere molteplici risultati come fornire informazioni, ma anche aumentare la brand awareness, raccogliere lead e vendere. Perché no!
Tra tutti i social media Facebook è sicuramente quello più indicato per effettuare un lancio di vendita.
La differenza con il social precedente è lampante perché su Instagram le parole devono cedere il posto ai contenuti visivi.
È importante inserire un breve testo sotto ogni post, ma ricorda che gli utenti non navigano su questa piattaforma per leggere.
Scegli una o più foto d’impatto oppure, meglio ancora, pubblica un video.
Può essere un’anteprima in cui consigli di leggere o vedere il contenuto completo su un’altra piattaforma.
Instagram deve mostrare, ispirare ed emozionare. Gli utenti cercano questo e tu devi sapere esattamente cosa dargli per ottenere quanto più seguito possibile.
Su Instagram ti consiglio di sfruttare anche il potere delle storie per mostrate backstage, tutorial o spezzoni di vita quotidiana aziendale.
Passiamo ora al social media delle opinioni e dei professionisti. Esattamente come Facebook ti consente di pubblicare una grande quantità di contenuti, anche se più immediati.
I testi, ad esempio, non devono superare un certo numero di caratteri ed è molto importante utilizzare sapientemente gli hashtag per permettere ad altri esperti o appassionati di trovare i tuoi tweet.
Su Twitter puoi mostrarti un esperto del tuo settore condividendo opinioni, punti di vista o prese di posizione su argomenti riguardanti la tua nicchia di mercato.
Attraverso questo social media puoi anche entrare in contatto con altre personalità del tuo ambito e creare un network molto utile alla tua azienda.
Ci siamo spostati da social media più personali ad altri più professionali. Ora vediamo quello che per definizione aiuta gli imprenditori a creare una rete di contatti.

Siamo arrivati al social network professionale per eccellenza sul quale si trovano la maggior parte delle aziende a livello mondiale.
Seguire una guida LinkedIn può essere molto utile per muovere i primi passi all’interno di questa piattaforma creata per fare rete.
LinkedIn è stato ideato appositamente per dare vita ad un utile reticolato di conoscenze all’interno della tua nicchia di mercato, questo è anche il motivo per cui la piattaforma evidenzia i gradi di collegamento tra diversi utenti.
Oltre a fare questo, puoi pubblicare dei contenuti che però devono essere necessariamente a carattere professionale.
Proprio come accade su Twitter, condividere articoli e opinioni su LinkedIn ti aiuta a mostrarti come un esperto del settore, allargando la tua cerchia di contatti.
Affiliate Marketing
L’Affiliate marketing è quel processo attraverso il quale puoi vendere il tuo prodotto o servizio attraverso una rete di affiliati, i quali ne ricavano una percentuale.
Hai già capito di cosa sto parlando? Di una rendita passiva.
D’altronde, è il sogno di tutti quello di riuscire a guadagnare anche mentre si dorme.
Grazie all’Affiliate marketing questo è possibile. Ogni vendita realizzata attraverso gli annunci permette all’affiliato sul cui sito è stata inserita la pubblicità di guadagnare una commissione concordata in precedenza con il proprietario del prodotto o servizio.
Come funziona tutto questo processo?
Ad essere interessati sono 4 soggetti:
- Creatore del prodotto o servizio: la prima figura importante è colui che crea il prodotto o del servizio che verrà pubblicizzato.
- Editore: è il soggetto che mette a disposizione il suo sito web per la pubblicazione dell’inserzione attraverso la quale guadagnerà la commissione.
- Rete: affinché tutto questo procedimento funzioni, è fondamentale Internet.
- Cliente: il consumatore finale è l’ultimo soggetto indispensabile perché grazie alla vendita permette all’editore di guadagnare la sua commissione.
Quando parliamo di affiliate marketing non ci stiamo riferendo solo ed esclusivamente alla classica idea di banner pubblicitario. Può manifestarsi anche come un link all’interno di un testo informativo che induce l’utente a cliccare.
Questa forma di marketing permette di pubblicizzare un prodotto o un servizio su più piattaforme appartenenti a proprietari diversi.
Mobile Marketing
Il Mobile marketing è quella strategia di marketing digitale che tra tutti i canali web sceglie di intercettare i potenziali clienti proprio dove passano la maggior parte del loro tempo: sullo smartphone.
Le statistiche sono chiare in proposito. Pensa solamente al fatto che il 95% delle persone cerca le informazioni di cui ha bisogno attraverso lo smartphone.
Ricorda che una strategia di marketing efficace è quella che intercetta il pubblico esattamente nel luogo in cui si trova.
In realtà, il Mobile marketing non è una branca a sé. Si compone piuttosto di tutte le strategie che abbiamo appena visto come l’E-mail marketing, il sito web ottimizzato, l’invio di SMS, le notifiche push o in app per raggiungere gli utenti dove si sentono più a loro agio.
Appare chiaro come il Mobile marketing si preoccupi di rendere tutte le strategie ottimizzate per i dispositivi mobili, come gli smartphone.
Ma fa anche molto più di questo. SI occupa di tenere traccia dei comportamenti degli utenti per restituirti dei dati attendibili sulla base dei quali puoi affinare la tua strategia.
Ignorare la tecnologia mobile sarebbe un grande errore perché non si tratta di un fenomeno passeggero, quanto di un ambito della vita di ognuno di noi che potrà solamente ampliarsi nel futuro più prossimo.
Funnel Marketing
Una delle strategie principali del web marketing è il funnel marketing, la cosiddetta strategia dell’imbuto.
Come mai viene chiamata ad imbuto?
Immagina che il tuo pubblico si trovi tutto sul lato più ampio. Inizia a precipitare all’interno e, dopo una serie di passaggi, fuoriesce dalla strettoia sul lato opposto.
Questo è esattamente ciò che fa il funnel marketing. Il suo obiettivo è quello di attrarre il pubblico aumentando la brand awareness.
Dopodiché, i potenziali clienti devono passare attraverso le fasi di considerazione, di conversione (in cui acquistano) e successivamente di fedeltà al marchio.
Il principio è quello di riuscire a trovare, all’interno di tutto il tuo pubblico, quel gruppo di persone in grado di arrivare fino alla fase dell’acquisto.
All’inizio gli utenti si fanno un’idea del marchio, poi il loro interesse aumenta fino a diventare un desiderio che alla fine si concretizza nell’azione di acquisto.
Le basi del funnel marketing sono le stesse da decenni, tuttavia oggi devono essere applicate alle tecnologie digitali per far sì che questo processo si svolga completamente sul web.
Come impostare una strategia di web marketing
Il web marketing comprende una serie di discipline e dipende da te, insieme agli esperti a cui ti rivolgi, creare la strategia adatta per la tua attività.
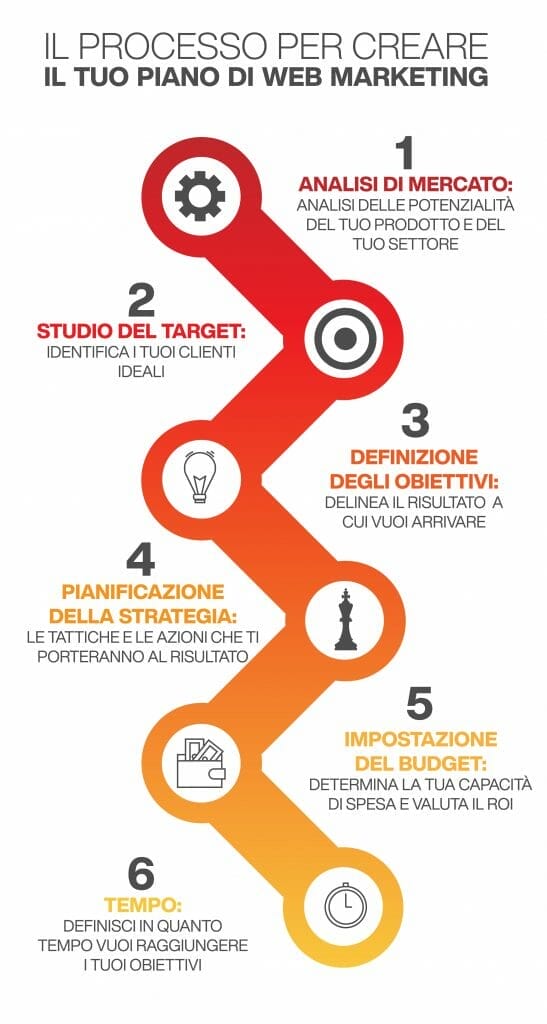
Adesso vediamo in breve tutto il processo che devi prendere in considerazione per poter impostare in maniera efficace il tuo piano di web marketing.
- Analisi di mercato: il primo passo è quello di fare un’analisi di mercato. Valuta i tuoi prodotti o servizi e la loro potenzialità all’interno del mercato. Fai un’autovalutazione e mettiti a confronto con i tuoi competitor per capire se ci sono vie libere in cui inserirti portando qualche novità;
- Studio del Target: successivamente si passa quello che è lo studio del target, o profilazione della buyer persona. Identifica i potenziali clienti a cui vuoi rivolgerti perché pensi che con la tua offerta potrai risolvere un loro problema o soddisfare un loro desiderio;
- Definizione degli obiettivi: fatto ciò passa alla definizione degli obiettivi che vuoi raggiungere. È utile anche per misurare la qualità delle tue performance. Come si fa a scegliere degli obiettivi validi? Identificali utilizzando la tecnica S.M.A.R.T. acronimo di: specifico, misurabile, accessibile, realistico, tempestivo. Queste sono le caratteristiche che deve rispettare ogni tuo obiettivo;
- Pianificazione della strategia: fatte le analisi preliminari, ecco che arriva il momento di scegliere le azioni e le tattiche specifiche per il tuo piano di web marketing. Quindi devi individuare gli strumenti e i canali che intendi utilizzare per promuovere il tuo brand;
- Impostazione del budget: scegli come allocare il budget. Programma i tuoi investimenti per ogni canale e strumento, ma tieni d’occhio gli andamenti per capire come procedere;
- Tempo: stabilisci in quanto tempo vuoi arrivare ai tuoi obiettivi a breve, medio e lungo termine. Fare delle previsioni è utile anche per gestire al meglio il budget.
Queste azioni preliminari sono le basi su cui puoi iniziare a costruire ognuna delle singole strategie di web marketing che vedremo ora.
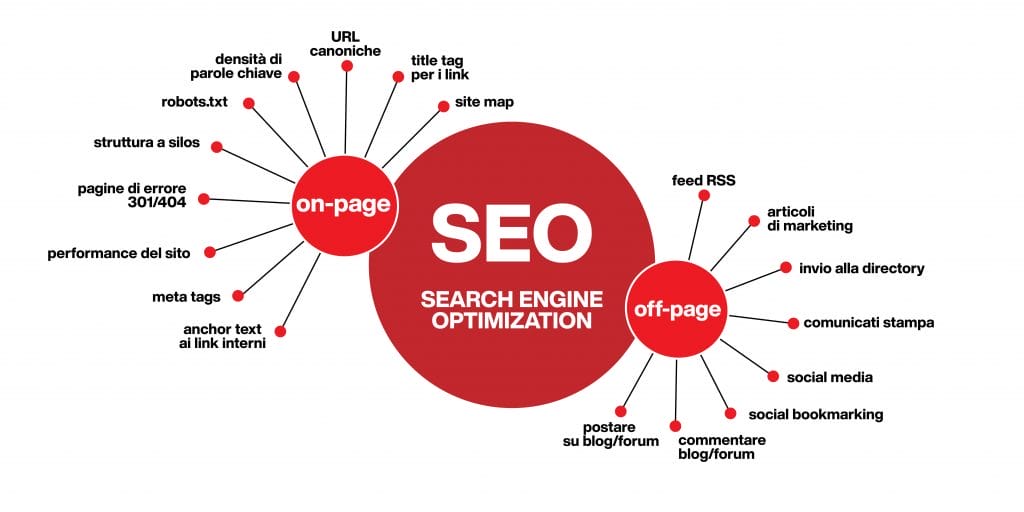
Strategia SEO
In ambito di ottimizzazione dei motori di ricerca ci sono due grandi settori di cui tenere conto: quello della SEO On-page e quello della SEO off-page.
L’ottimizzazione SEO On-page si concentra sui contenuti che si trovano sul tuo sito, quindi le tue pagine web e i tuoi articoli di blog.
È necessario creare dei contenuti che rispettino determinate regole e che siano riconosciuti da Google come pertinenti.
Si tratta fondamentalmente di creare testi ottimizzati che contengano quelle che sono considerate le parole chiave inerenti al tuo settore e al tuo prodotto o servizio. Ovvero quelle parole per le quali desideri essere trovato dagli utenti che effettuano le loro ricerche sul web.
La SEO è una disciplina complicata e richiede studio, preparazione ed esperienza. Lo so perché per quanto io ne sappia di strategie di ottimizzazione, c’è lo specialista SEO del mio team ne sa una più del diavolo.
Ma la SEO non finisce qui…
Esiste tutto un altro mondo legato all’ottimizzazione delle tue pagine, sto parlando della SEO Off-page.
Sono tutte quelle attività che puoi fare fuori dal tuo sito e dalle tue pagine web e che ti servono per aumentare il posizionamento del tuo sito sui motori di ricerca.
Ci sono vari modi in cui la SEO Off-page entra in gioco, per esempio la diffusione di link che portano al tuo sito web ma inseriti in articoli pubblicati in altri portali, detti guest post, che vengono pubblicati su blog altrui ma che contengono link che portano alle tue pagine web.
Come per ogni strategia, la SEO off-page deve essere fatta ad hoc e, siccome si tratta di cose piuttosto tecniche, è bene che se ne occupi un professionista. Solo così avrai la sicurezza che venga fatto un buon lavoro.
Strategia PPC
Appena inizierai a lavorare con la SEO ti accorgerai ben presto che la strada per ottenere la visibilità non è così veloce.
Un lavoro di SEO ben fatto sul tuo sito web ti consente di ottenere un flusso costante di utenti nel tempo. Ma se hai bisogno di visibilità nell’immediato?
La tua strategia SEO dev’essere integrata con una strategia PPC.
Ricordi quando prima abbiamo parlato delle campagne a pagamento dove paghi solo quando gli utenti cliccano sui tuoi annunci? Ecco, questo è esattamente ciò di cui hai bisogno.
Quando intendi impostare una campagna PPC devi, prima di tutto, capire quale tipologia di annuncio vuoi pubblicare, se search o display.
Se sei all’inizio, ti consiglio di partire con una campagna search e poi passare alla creazione di banner per la pubblicità display.
Per trovare le parole chiave da utilizzare nella tua campagna PPC devi capire cosa cercherebbe un ipotetico utente su Google.
Dopo aver capito qual è il focus, devi capire come l’utente lo cercherebbe.
Questa fase preliminare di scelta dei termini è molto importante per riuscire a colpire un bacino di utenza ampio ma anche definito per la tua nicchia di mercato.
Quando realizzi una campagna PPC nel web marketing devi tenere presente la grande importanza della creazione di una landing page, ossia una pagina di atterraggio su cui gli utenti arrivano cliccando il link presente nel tuo annuncio.
Non sottovalutare questo aspetto perché se la landing page non li convincerà, difficilmente otterrai una conversione e avrai perso una parte di investimento. Tutto deve essere curato nei minimi dettagli.
Strategia di Content Marketing
Il content marketing è cruciale in tutte le attività di web marketing. Non riguarda solo la creazione di contenuti fini a sé stessi, ma devono essere contenuti di qualità per offrire valore all’utente.
I contenuti possono essere di vari tipi, infatti non parlo sono di testi ma anche di immagini, video, infografiche, guide, ebook e così via. Ogni contenuto si distingue per le sue capacità di coinvolgere, interessare, emozionare e trascinare l’utente. Il tuo obiettivo è di veicolare quei messaggi che attirino i consumatori e gli diano una motivazione per interessarsi al tuo brand.
Perciò, la tua comunicazione non deve focalizzarsi sul tuo prodotto o servizio, ma sul problema o il desiderio del potenziale cliente. I consumatori non comprano da te per le caratteristiche dei tuoi prodotti, o comunque non solo. Il loro interesse è di trovare una soluzione ad una problematica oppure ottenere il risultato a cui aspirano.
Per questo ogni contenuto deve essere modulato ad hoc sul profilo dei tuoi potenziali clienti. Ognuno ha bisogni diversi e cerca delle soluzioni che siano pensate proprio per lui ed è questo che tu gli devi offrire.
Inoltre, il content marketing è molto utile in ottica SEO. Ricorda sempre che bisogna scrivere sia per il motore di ricerca sia per gli utenti.
Il contenuto inoltre gode di forze proprie che potrebbero entrare in gioco, valorizzando le tue performance con grande efficacia.
Per esempio la viralità, ovvero quando un contenuto in brevissimo tempo viene visto da un numero impressionante di utenti.
La condivisibilità, cioè quanto viene stimolato il passa parola digitale e il contenuto rimbalza di utente in utente spontaneamente.
L’originalità, grazie alla quale i tuoi contenuti emergono dal mare di quelli dei competitor e attirano l’attenzione degli utenti.

Strategia di E-mail Marketing
Abbiamo detto che l’e-mail marketing è il mezzo, insieme ai social media, per creare un rapporto più intimo con il tuo pubblico.
Ma non è l’unico vantaggio…
Questi utenti sono altamente profilati e targettizzati, per cui rappresentano un pubblico sul quale poter avere un ROI più alto.
Sai perché? Perché sono consumatori che si sono interessati al tuo prodotto o servizio e hanno deciso di lasciarti il loro contatto. Oppure sono clienti effettivi che hanno già acquistato da te e che tu hai la possibilità di fidelizzare nella fase post acquisto del processo di vendita.
Anche le tue e-mail fanno parte del tuo repertorio di contenuti, quindi non possono essere lasciate al caso.
Per fare arrivare ad ognuno il messaggio giusto sono due i concetti fondamentali da tenere a mente:
- Segmentazione;
- Personalizzazione.
La segmentazione si concentra sulla divisione dei contatti email in gruppi specifici, questo ti consente di indirizzare a queste persone dei contenuti specifici.
L’invio di e-mail generiche è molto difficile che generi interesse, perché non si rivolge veramente a nessuno.
Ecco che entra in gioco la personalizzazione, che è uno dei fattori maggiormente importanti per email e campagne pubblicitarie di successo. Solo così riuscirai ad attirare l’attenzione dei tuoi clienti e tenerli vicini al tuo brand il più a lungo possibile.
Questo è un modo per allungare il ciclo di vita dei tuoi clienti, ovvero riuscire a concludere con ognuno di loro un maggior numero di vendite.
Attraverso le e-mail puoi tenerli informati delle novità, fargli offerte di prodotti o servizi correlati a quelli che hanno già acquistato e fargli avere dei buoni o promozioni. Questo è un buon modo per gratificare i tuoi clienti e fargli sapere che non ti sei dimenticato di loro.
Strategia di Social Media Marketing
Quando decidi di implementare il social media marketing nella tua strategia di web marketing, devi considerare che ogni social network ha regole e dinamiche differenti, oltre che un vero e proprio linguaggio di comunicazione e modalità di fruizione.
La differenza di utilizzo di questi strumenti vale sia per i consumatori sia per chi, come te, vuole sfruttarli per il business.
I consumatori non sono più fruitori passivi, sono sempre più informati, consapevoli e partecipi ai processi economici che li riguardano. Inoltre, il loro scopo non è solo l’informazione ma anche la divulgazione.
Si scambiano e condividono le notizie, lasciano recensioni e si sentono sempre più autorizzati a dare la propria opinione, influenzando le sorti delle vendite.
Agire nei contesti in cui gli utenti svolgono queste azioni significa entrare in diretto contatto con loro e potenzialmente generare conversazioni.
Queste sono molto utili per il tuo business, infatti il mercato sta diventando sempre di più conversazionale e le vendite funzionano se costruisci rapporti di fiducia con i tuoi clienti.
I social media sono i canali ideali per creare questi dialoghi a doppio senso. Tu puoi far girare le tue promozioni in modo rapido sulle piattaforme e i tuoi clienti possono contattarti quasi in maniera diretta per ricevere assistenza.
L’assistenza clienti è diventato un requisito fondamentale affinché il tuo brand venga scelto.
Inoltre, le piattaforme social sono canali proficui dove puoi pianificare le tue strategie di canalizzazione di vendita per attirare un maggior numero di utenti da convertire in tuoi clienti.
Strategia di Affiliate Marketing
Puoi sfruttare l’affiliate marketing per aumentare notevolmente le tue vendite, insieme alle altre strategie che compongono il web marketing.
Come mai? Perché questa tecnica sfrutta il potere dell’influenza.
Ci sono alcuni elementi a cui devi fare attenzione e che, se ben gestiti, possono aiutarti a raggiungere il massimo risultato con il minimo sforzo.
Uno degli aspetti principali di cui ti devi preoccupare quando fai affiliate marketing è quello di scegliere i giusti affiliati. Se sbagli questo passaggio rischi di vanificare tutto il resto della strategia e, ovviamente, anche l’investimento.
Gli affiliati che scegli devono rientrare nella tua nicchia di mercato, ovviamente. Ma oltre a questo devono avere anche un buon seguito, un coinvolgimento alto e un sincero rapporto con il pubblico.
Dopo aver scelto gli affiliati che ti aiuteranno ad aumentare le vendite, devi decidere come vuoi incentivare le conversioni.
Puoi proporre delle offerte oppure dei coupon, che agli utenti piacciono davvero tanto. Nel momento in cui uno di loro clicca sul link che hai fornito al tuo affiliato, può automaticamente sfruttare il coupon con uno sconto.
Tutto questo processo funziona molto bene se scegli di appoggiarti a degli influencer, ossia a quelle personalità del web che hanno un seguito ampio e fidelizzato, il quale segue ciecamente i consigli che questi personaggi elargiscono.
L’affiliate marketing è efficace nel momento in cui riesci a creare una rete di affiliati robusta che ti consenta di impostare il tutto una volta e poi di godere per diverso tempo dei frutti, ricordandoti sempre di corrispondere una percentuale agli affiliati per l’aiuto che ti danno con la pubblicità.
Strategia di Mobile Marketing
Una strategia di mobile marketing può basarsi su diversi supporti come le app mobili, gli annunci, le ricerche da mobile, l’e-mail marketing, ma questo è tutto inutile se il tuo sito web principale non è ottimizzato per i dispositivi mobili.
Il primo aspetto che devi curare all’interno della tua strategia è quello di creare un sito web reattivo, veloce e dinamico.
Le pagine web devono adattarsi alla visualizzazione da mobile, qualunque sia la dimensione dello schermo di uno smartphone.
Se non hai ancora un sito responsive, ti consiglio vivamente di attivarti in questo senso. È fondamentale sia per essere agevolato da Google sia per migliorare l’esperienza utente.
Inoltre, se il tuo sito prevede un’area in cui gli utenti possono registrarsi per la creazione di un account, dai la possibilità di svolgere questo passaggio anche tramite social per rendere il tutto più immediato.
Allo stesso modo, inserisci delle opzioni di pagamento tramite cellulare, più dinamiche rispetto ai metodi classici. A nessuno piace trascorrere attraverso tante pagine, soprattutto quando si acquista da mobile e si ha poco tempo a disposizione per i diversi passaggi.
Nella creazione delle pagine web sul tuo sito ricorda che devi concentrarti sulla SEO mobile e sulle ricerche che gli utenti effettuano da smartphone.
Pensa che, in generale, tutte le azioni veloci come inviarti un messaggio, chiamarti, accedere al tuo sito web da un’immagine ed effettuare ordini tramite app, sono elementi che facilitano l’esperienza utente da smartphone e che, di conseguenza, lo inducono ad effettuare quell’azione che tanto desideri.
Oltre allo sviluppo di un sito web mobile friendly, puoi anche pensare di sviluppare un’app per facilitare gli acquisti. Questa strategia funziona molto bene se hai un e-commerce.
Strategia di Funnel Marketing
Eccoci di nuovo al nostro famoso imbuto, il funnel marketing. Abbiamo spiegato da quali parti è composto, ma non abbiamo approfondito la strategia da applicare.
Per ogni diversa fase esistono delle specifiche tecniche che puoi mettere in campo per condurre i potenziali clienti lungo l’imbuto fino a completare l’acquisto.
Inizialmente devi mettere il pubblico nella condizione di conoscere il tuo marchio.
Come fare tutto ciò? Attraverso diversi strumenti come la SEO per aumentare le ricerche organiche, l’attività sui social media, il content marketing, i forum, i link sui guest post, le e-mail, ecc.
In questa fase puoi anche puntare sulla pubblicità a pagamento, come il PPC, o sull’affiliate marketing.
Dopodiché, passiamo alla fase della considerazione in cui i potenziali clienti ti conoscono ma devono farsi un’idea ben precisa di te, della tua azienda e dei tuoi prodotti o servizi. Per fare questo puoi sfruttare l’influencer marketing, le recensioni e le testimonianze di clienti che hanno già acquistato.
Arrivi così a dover gestire la fase della conversione. Qui devi concentrarti sul convogliare il pubblico verso il processo di iscrizione o di inizio della procedura per giungere poi all’acquisto.
Dopo aver ottenuto la conversione devi abbandonare nel dimenticatoio i tuoi clienti? Assolutamente no!
È di fondamentale importanza mantenere con loro un legame attraverso e-mail personalizzare, messaggi in app, promozioni particolari, customer service, ecc.
Infine, l’ultimo passaggio è quello della retention dove devi fidelizzare il cliente e rafforzare l’immagine aziendale. Questo può essere fatto con integrazioni del prodotto o servizio, messaggi di ringraziamento, eventi particolari, ecc.
Ora conosci le migliori strategie da implementare in ogni ambito del web marketing. Tuttavia, per poterle applicare al meglio il mio consiglio è di rivolgerti ad un professionista che sappia consigliarti le strade più giuste da seguire nel tuo caso specifico.

Perché rivolgersi ad un esperto di Digital Marketing
Il consulente di web marketing è una figura professionale che aiuta le aziende ad innovarsi e a trovare nuovi modi per continuare a crescere.
Quindi, se hai un’attività, un’azienda, un e-commerce o se sei un libero professionista ormai avrai capito che devi essere presente sul web per trovare clienti. Inoltre, abbiamo visto che il marketing online è fatto da tante e svariate strategie ognuna delle quali ha dei professionisti specifici che se ne occupano.
Il beneficio di rivolgersi a chi ti può dare i consigli giusti è che eviterai di perdere tempo prezioso a capire quello che devi fare. Un esperto ha già le competenze e le conoscenze per fare un’analisi della tua situazione e per poter valutare quale piano d’azione fa al caso tuo e del tuo business.
Chiedersi perché è necessario e vantaggioso rivolgersi ad un esperto in web marketing è un po’ come chiedersi il perché è necessario andare dal parrucchiere. Se vuoi sistemarti i capelli sono sicuro che sceglierai un professionista del settore a cui affidarti. Quindi, se vuoi aumentare le performance del tuo business occorre chiedere la consulenza di chi lavora ogni giorno in quell’ambito. Se per qualche ragione tu non hai bisogno del parrucchiere, sono sicuro che lo consiglieresti a chiunque lo necessiti.
Tornando a noi, un progetto di web marketing deve essere strutturato a 360 gradi perché le strategie funzionano al meglio quando vengono applicate insieme. Rivolgendosi ad un professionista è possibile impostare una pianificazione che tenga conto di tutte le necessità del tuo business, oltre al raggiungimento di obiettivi specifici e misurabili. Insomma, quello che ti garantisce un esperto è un supporto completo in tutte le fasi del processo che ti porterà ad aumentare la tua notorietà, i tuoi clienti e ad ottenere maggiori profitti.
Tutto questo con la sicurezza di andare nella direzione giusta, senza perdere tempo e con la possibilità di capire subito quando qualcosa non funziona così da metterla subito a posto. È questo l’approccio vincente per far funzionare realmente l’attività.
I libri che ti consiglio sul Web Marketing
Uno dei metodi migliori per gettare le giuste basi e continuare a mantenersi aggiornati è quello di leggere libri di esperti del settore.
Dico sempre che un imprenditore non ha mai finito di imparare e anch’io ogni giorno dedico parte del mio tempo alla lettura.

Ecco i libri migliori su cui puoi approfondire l’ambito del web marketing:
- Marketing 4.0 (Dal tradizionale al digitale) – Philip Kotler: se vuoi approfondire il web marketing questo libro è un caposaldo. L’autore è stato uno dei padri del marketing e in questo testo spiega come sia avvenuto il passaggio dal marketing tradizionale a quello digitale e come siano cambiati i comportamenti dei consumatori.
- Le 22 immutabili leggi del marketing (Se le ignorate, è a vostro rischio e pericolo!) – Al Ries & Jack Trout: il marketing in generale ha delle regole sempre valide che non puoi assolutamente permetterti di ignorare. Con maestria gli autori hanno raccolto in questo libro l’esperienza di una vita restituendoti un manuale da seguire come la bibbia del marketing.
- Le armi della persuasione – Robert Cialdini: ora passiamo all’aspetto più psicologico del web marketing con un’altra pietra miliare. All’interno di questo libro scoprirai quali sono le tecniche in grado di far compiere qualsiasi azione tu voglia ai tuoi clienti.
- Come trattare gli altri e farseli amici – Dale Carnegie: i libri di Carnegie sarebbero tutti da leggere, ma questo in particolare è utile per comprendere come dall’altra parte si trovino delle persone e quali siano le tecniche migliori per creare un rapporto sano e sincero.
- Neuromarketing e scienze cognitive per vendere di più sul web – Andrea Saletti: all’interno di questo libro tutto italiano puoi scoprire quanto il customer journey sia dettato più da scelte emotive che cerebrali. L’autore ti spiega quali sono e come sfruttare queste fasi decisionali.
È arrivato il momento di concretizzare i tuoi risultati
Il web marketing rappresenta il presente e il futuro. Si tratta dell’evoluzione e dell’attuazione delle strategie di marketing, ma attraverso il digitale e i suoi strumenti.
I canali di comunicazione sono cambiati e anche il modo in cui i consumatori prendono le loro decisioni di acquisto. Se hai un’attività hai bisogno di accogliere queste forme di potenziamento per riuscire a crescere nel panorama odierno.
Quello che ti serve è il giusto piano di web marketing che permetterà al tuo business di mettersi il vestito nuovo di cui ha bisogno per restare all’interno del mercato.
Il digital marketing non è più un’opzione, è diventato una priorità di cui le aziende che vogliono crescere non possono più fare a meno.
E tu sei pronto ad affrontare questa evoluzione con successo?
Clicca il pulsante qui sotto e prenota la tua consulenza personalizzata. Imposteremo la strategia che meglio si adatta alle tue necessità e ai tuoi obiettivi.

Mirko Cuneo
Aiuto aziende e professionisti a potenziare il proprio business, in modo che possano aumentare i propri guadagni, clienti e la rispettabilità del proprio brand.
Ti serve aiuto? Clicca QUI

